

Il modo migliore per cercare doppioni dipende dal tipo e da cosa dovrebbe accadere ai doppioni trovati:
- Ricerca di duplicati e indirizzi duplicati (deduplica) con DataQualityTools:
Se si desidera particolare comodità o se i doppioni da ricercare sono difficili da trovare, non si può fare a meno di un software appositamente progettato per questo problema. I DataQualityTools trovano doppioni anche se in una certa misura diversi tra loro. Ciò è particolarmente utile per le liste di indirizzi, dove gli errori ortografici e le variazioni ortografiche sono la regola piuttosto che l'eccezione. Maggiori informazioni ... - Soppressione dei duplicati con il comando 'distinct':
Se si tratta di valori duplicati facili da trovare, ad esempio codici di clienti o articoli duplicati, e si desidera semplicemente sopprimerli nel risultato di una ricerca nel database, è possibile utilizzare il comando SQL 'distinct'. Maggiori informazioni ... - Nascondere i duplicati con il comando 'group by':
Se si tratta di valori duplicati facili da trovare, ad esempio codici di clienti o articoli duplicati, e si desidera semplicemente nascosto nel risultato di una ricerca nel database, è possibile utilizzare il comando SQL 'group by'. Maggiori informazioni ... - Ricerca di duplicati con il comando 'select':
Se si tratta di valori duplicati facili da trovare, ad esempio codici di clienti o articoli duplicati, e se le corrispondenze trovate devono essere cancellate direttamente dal database o le serie di dati devono essere completate e compilate sulla base del risultato, si può utilizzare il comando SQL 'select'. Maggiori informazioni ...
1. Ricerca di duplicati e indirizzi duplicati (deduplica) con DataQualityTools in Azure SQL
I DataQualityTools trovano doppioni anche se in una certa misura diversi tra loro. Ciò è particolarmente utile per le liste di indirizzi, dove gli errori ortografici e le variazioni ortografiche sono la regola piuttosto che l'eccezione. In questo caso procedere come segue:
- Se non si è già provveduto, da qui è possibile scaricare il DataQualityTools gratuitamente. Installare il programma e richiedere un'attivazione test. In questo modo può lavorare con il programma per una settimana senza alcuna limitazione.
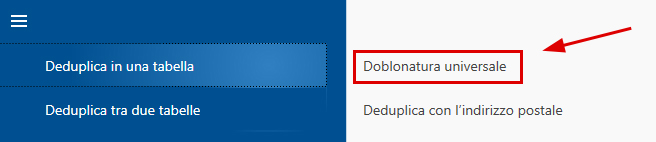
- La funzione che ci occorre si trova nel menu, nel blocco 'Deduplica in una tabella'. Lì selezioniamo 'Doblonatura universale'.
- Dopo aver chiamato questa funzione, viene innanzitutto visualizzata la gestione progetti. Inserire qui un nuovo progetto con un nome di progetto a piacere e quindi fare clic sul pulsante di comando 'Avanti'.
- Il passo successivo consiste nel selezionare l'origine dei dati con i dati da elaborare. A questo scopo, selezionare Azure SQL dall'elenco di selezione sotto 'Format / Accesso a'.
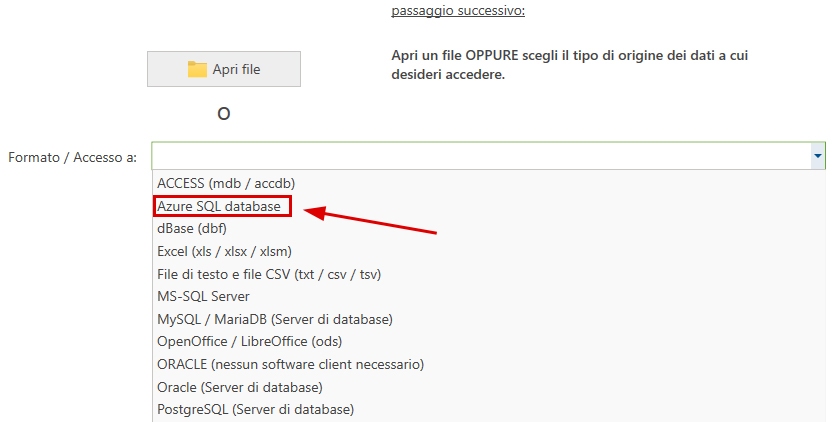
Inserire infine il nome del server database. Dopo aver fatto clic sul pulsante di comando 'Connessione al server', inserire i dati di accesso. Il database e la tabella desiderati infine si selezionano dalle relative liste. - Quindi dire al programma quali colonne della tabella si desidera confrontare:
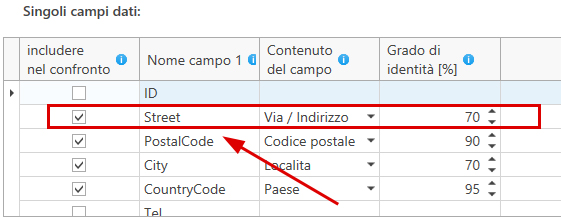
In questo esempio, tra le altre si deve confrontare la colonna 'Street'. Questa colonna contiene il nome della via, motivo per cui è stata scelta 'Via' dall'elenco di selezione per il contenuto del campo. Come soglia per il fattore di corrispondenza è stato scelto il 50%. Il nome della via deve quindi corrispondere almeno del 50%, in modo che la serie di dati in questione far parte nel risultato.
Se necessario, anche singole colonne possono essere combinate per formare un gruppo:
I contenuti delle colonne sono poi riassunti nel gruppo prima del confronto e sono quindi confrontati tra loro. - Con un clic sul pulsante 'Avanti' si accede a una finestra di dialogo con ulteriori opzioni. In questo caso, tuttavia, non ci servono.
- Facendo clic sul pulsante 'Avanti' ha quindi inizio la ricerca di duplicati che in breve visualizzerà un riepilogo del risultato. Se nella tabella da elaborare il programma ha trovato dei duplicati, poi un clic sul pulsante 'Mostra / modifica risultati' porta ad una panoramica del risultato:

Il risultato della deduplica qui appare in forma di tabella in cui i record di dati da cancellare sono contrassegnati con una croce rossa, che se necessario può essere eliminata. - Infine, il risultato deve essere ulteriormente elaborato. Per esempio, potremmo contrassegnare le serie di dati contrassegnate per la cancellazione direttamente nella tabella sorgente in Azure SQL con un segno di cancellazione. A questo scopo, selezioniamo la funzione appropriata cliccando prima su 'Funzioni di marcatura':

Quindi su 'Marcare nella tabella di origine':
Infine, si deve specificare come debba apparire concretamente il contrassegno e in quale campo dati debba essere scritto:
2. Soppressione dei duplicati con il comando 'distinct' in Azure SQL
Si ipotizzi che dalla tabella con gli articoli ordinati si debbano determinare tutti i codici degli articoli che un singolo cliente ha ordinato, per cui nel risultato ogni codice di articolo può manifestarsi con un cliente solo una volta. In questo caso la ricerca nel database potrebbe essere simile a questa:
SELECT DISTINCT customer_id, article_no
FROM customer_articles
ORDER BY customer_no, article_no
Il termine 'distinct' si riferisce a tutte le colonne specificate in 'select'. Di conseguenza, ogni codice articolo viene elencato con ogni codice del cliente, ma ogni combinazione di codice articolo e codice cliente viene elencata una sola volta. In combinazione con il comando 'into' è anche possibile pulire una tabella di serie di dati duplicati:
SELECT DISTINCT customer_id, article_no
INTO table_new
FROM customer_articles
ORDER BY customer_no, article_no
I dati eliminati dai doppioni vengono scritti in una nuova tabella.
3. Nascondere i duplicati con il comando 'group by' in Azure SQL
Si ipotizzi che dalla tabella con gli articoli ordinati si debbano determinare i codici degli articoli, per cui nel risultato ogni codice di articolo può manifestarsi solo una volta. In questo caso la ricerca nel database potrebbe essere simile a questa:
SELECT article_no, COUNT(*), SUM(revenue)
FROM invoice_articles
GROUP BY article_no
ORDER BY COUNT(*), article_no
Oltre al codice articolo, questa ricerca restituisce il numero delle serie di dati che contengono questo codice articolo e la somma delle vendite di queste serie di dati.
4. Ricerca di duplicati con il comando 'select' in Azure SQL
I duplicati univoci, ovvero i record di dati doppi nei quali tutte le occorrenze coincidono carattere per carattere a eccezione di minuscole/maiuscole, si possono trovare con relativa facilità utilizzando le query SQL. Nella seguente query, ad esempio, il Azure SQL restituisce tutti i record di dati per i quali il campo dati 'name' coincide:
SELECT tab1.id, tab1.name, tab2.id, tab2.name
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name)
Come si può vedere, per questa query SQL occorre una colonna con un ID che identifichi in modo univoco il relativo record di dati, così da evitare il confronto di un record di dati con sé stesso. Tale ID inoltre è necessario per assicurare che il record di dati con l'ID maggiore compaia unicamente nella colonna 'tab1.id' e non anche nella colonna 'tab2.id'. Questo sistema garantisce che il record di dati con l'ID maggiore di un gruppo di duplicati non venga cancellato. Gli ID dei record di dati da cancellare sono contenuti nella colonna 'tab2.id'. Integrato in un comando DELETE per il Azure SQL, il risultato sarà:
DELETE FROM tablename
WHERE id IN
(SELECT tab2.id
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name))
Questo comando SQL naturalmente si può ulteriormente ampliare, in modo che parallelamente al contenuto del campo di dati 'name' vengano confrontati anche altri campi dati, come i campi dati che insieme contengono l'indirizzo postale.
Le opzioni offerte da SQL per la ricerca di duplicati fuzzy sono descritte nell'articolo 'Ricerca fuzzy di duplicati con SQL'. Questo problema può essere risolto in maniera soddisfacente solo con speciali strumenti che offrono una ricerca di record di dati doppi a tolleranza d'errore, come DataQualityTools.